Context Degradation Syndrome: When Large Language Models Lose the Plot
Tuesday November 26, 2024


Large language models (LLMs) have revolutionized the way we interact with technology. Tools like ChatGPT, Bard, and Claude can draft emails, summarize dense reports, generate code, and even brainstorm creative ideas. Their versatility and ability to process natural language have made them indispensable for countless tasks, from business communication to creative writing.
However, these models are not without their quirks. If you have spent enough time chatting with one, you may have noticed a curious phenomenon: after many exchanges–perhaps a hundred or more–the conversation seems to unravel. Responses become repetitive, lose focus, or miss key details. This shift can feel like the model is “losing the plot,” as once-sharp exchanges descend into frustrating incoherence.
This behavior is not just frustrating; it is fascinating. It reveals the underlying mechanics and limitations of how LLMs process and retain information. To give it a name, let us call this phenomenon Context Degradation Syndrome (CDS).
Context Degradation Syndrome (CDS) refers to the gradual breakdown in coherence and utility that occurs during long-running conversations with large language models (LLMs). This issue is not unique to ChatGPT; it can affect any AI system that relies on a finite context window. Once the conversation exceeds this limit, the model can no longer “remember” earlier exchanges in a meaningful way, leading to gaps, inconsistencies, and, occasionally, outright nonsense.
Importantly, CDS is not a bug. It is an inherent limitation of the underlying architecture of most LLMs, such as OpenAI’s GPT-4, Bard, Claude, and others. These models do not have true memory. Instead, they operate within a sliding window of recent text (or tokens) to generate responses. Any content that falls outside this window effectively vanishes, as though it never existed in the conversation.
CDS arises from several technical and practical factors that intersect in long conversations. These factors reveal not only the limitations of LLMs but also the design trade-offs that influence how they operate.
All LLMs function within a fixed context window that determines how much recent text they can “remember” at any given time. This context window is measured in tokens–units of text that include both words and punctuation. For example, GPT-4 supports a context window of approximately 8,000 to 32,000 tokens, depending on the version, while Claude can manage up to 100,000 tokens. However, no current model supports indefinite memory.
Once a conversation exceeds the token limit, earlier exchanges are dropped. Crucially, this does not discriminate between trivia and critical context; both are erased, even if highly relevant to the discussion. Imagine having a detailed conversation with someone, only for them to forget everything you said earlier once you reached a word limit–it can be disorienting and frustrating.
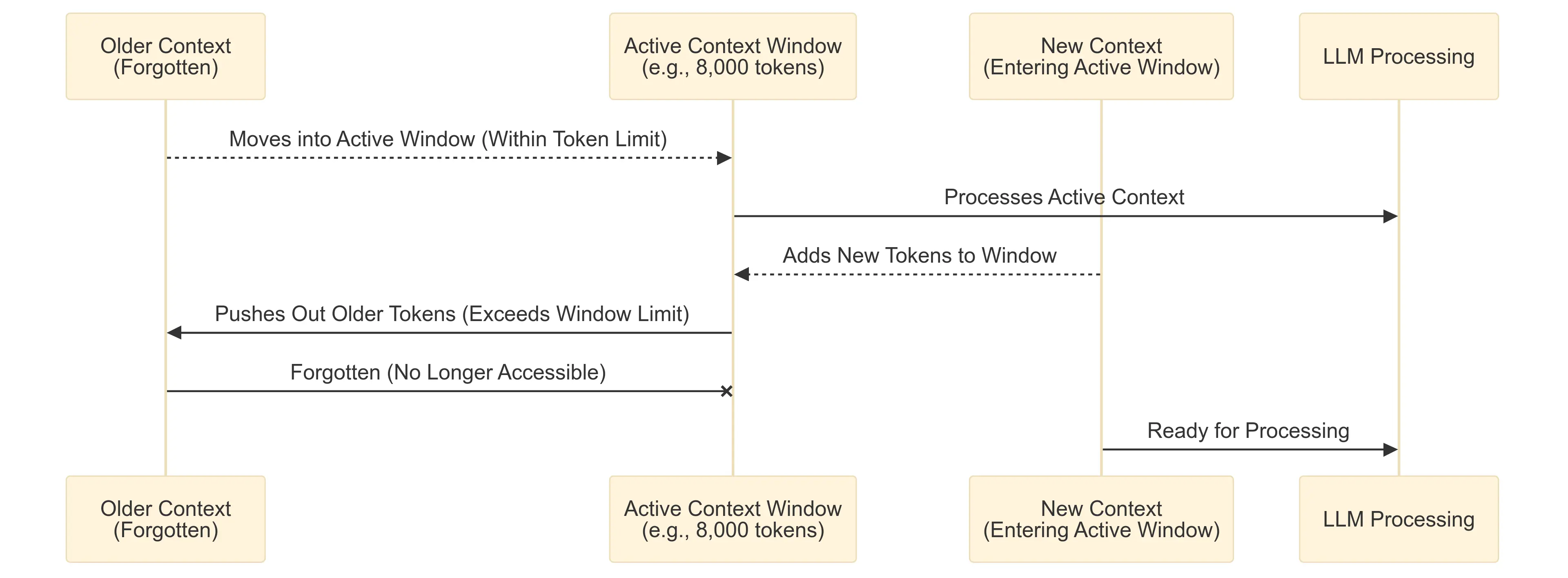
As conversations lengthen, small misinterpretations or irrelevant details can compound over time. Each response builds upon the last, meaning even minor misunderstandings early on can ripple into larger issues later. This “snowball effect” can make responses feel increasingly disjointed or irrelevant, contributing to the sense that the AI has “lost the plot.”
For example, if an LLM misinterprets a technical term in the 20th exchange, that misunderstanding may subtly influence all subsequent responses, leading to increasingly erroneous conclusions.
Unlike humans, who can reflect, reorganize thoughts, and take a step back when faced with complexity, LLMs process text sequentially and in isolation. They rely entirely on the information within their context window to generate each response. This makes them highly efficient at handling discrete, short tasks but leaves them vulnerable in long, intricate conversations where coherence across exchanges is crucial.
The lack of an overarching “big picture” understanding means that logical errors or contradictions can creep in as the conversation meanders or grows in complexity.
LLMs are trained with different objectives, which can influence how they handle extended discussions. For instance:
These design differences mean that the experience of CDS can vary across models, with some amplifying certain symptoms depending on their specific strengths and weaknesses.
The effects of CDS are not abstract; they manifest in specific, recognizable ways during long interactions with LLMs. Below are some common symptoms that users encounter:
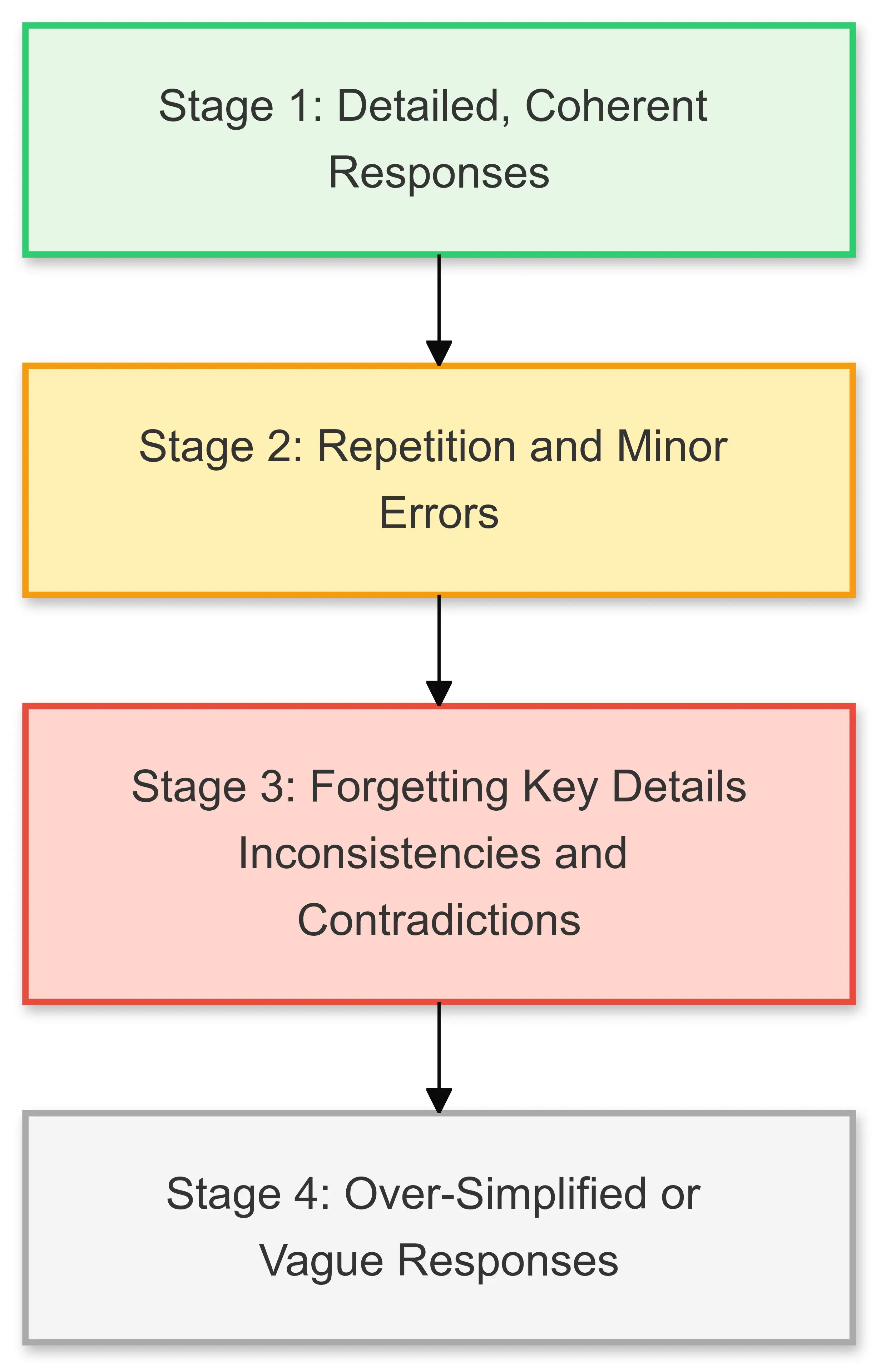
One of the most noticeable signs of CDS is when the model begins cycling back to the same points, even after the conversation has progressed. For example, you might ask for a nuanced explanation of a topic, but the model repeatedly summarizes basic information you already covered earlier. This repetition can feel like the AI is stuck in a loop, unable to integrate new context effectively.
Another hallmark of CDS is the model’s tendency to forget key details established earlier in the discussion. This can lead to:
This behavior is particularly problematic in technical or creative projects where consistency is crucial.
As the conversation grows longer, responses can become increasingly generic or vague. Early exchanges may have been rich in detail and nuance, but later responses often feel like shallow summaries or overly broad generalizations. For example:
This over-simplification can make the conversation feel less engaging and productive over time.
While CDS can be frustrating, there are several effective strategies to mitigate its effects and keep your conversations productive. By adapting your approach, you can maintain coherence and maximize the utility of LLMs.
Summarize Key Points
Periodically condense key details to help the LLM retain critical context
Use External Notes
Keep a separate document for critical information and refer to it as needed
Start Fresh Threads
Break long conversations into focused segments for better clarity
Choose the Right Model
Select LLMs optimized for long contexts to reduce the effects of CDS
Be Precise
Use clear, targeted prompts to reduce ambiguity and focus the model
Periodically summarizing key points for the model acts as a manual refresh. By condensing the critical elements of your discussion into a concise recap, you help the LLM stay focused on what matters most. For example:
This technique is particularly helpful in lengthy, multi-part discussions.
Keep a separate document or notes file to track important details from your conversation. You can reference these notes yourself or paste relevant excerpts back into the chat to reintroduce context that may have been lost. This approach is especially useful for:
By externalizing the memory burden, you free the LLM to focus on the immediate context while preserving the integrity of your discussion.
When a conversation becomes unwieldy or the model’s responses degrade significantly, starting a fresh thread can help. Reference the key points from the earlier discussion in the new thread to restore continuity. For example:
Breaking up discussions into shorter, focused sessions improves coherence and reduces the noise that accumulates over time.
Not all LLMs handle long contexts equally well. If you anticipate a lengthy or complex discussion, select a model optimized for extended interactions. For example:
Choosing a model suited to your needs can significantly reduce the risk of encountering CDS symptoms.
Use clear, targeted prompts to minimize ambiguity and help the model focus on what is most relevant. Avoid overly broad or open-ended questions that can lead the conversation astray. Instead:
Precision not only keeps the conversation on track but also reduces the likelihood of noise accumulating over time.
CDS is more than a technical inconvenience–it reveals fundamental trade-offs in the design of LLMs. These systems excel at processing recent text, leveraging vast amounts of data to generate coherent and contextually appropriate responses. However, they are not equipped for genuine long-term memory. This limitation underscores a broader challenge in AI development: balancing flexibility, efficiency, and coherence within finite computational resources.
CDS highlights the inherent constraints of current LLM architectures, particularly their reliance on context windows. These windows are optimized to manage immediate conversational needs but lack mechanisms for retaining critical details across extended exchanges. This trade-off reflects the complexity of designing systems that can handle both short-term precision and long-term context seamlessly.
Interestingly, CDS also mirrors aspects of human communication. Just as people can forget details or lose focus during sprawling conversations, LLMs struggle to maintain coherence as discussions grow in length and complexity. This parallel reminds us that even human communication requires resets, summaries, and deliberate efforts to regain clarity. Recognizing this similarity can help us adjust our expectations of LLMs and work with them more effectively.
The limitations of CDS are not insurmountable. As AI research continues to evolve, future models may overcome these challenges through innovations in architecture and memory management. Some promising areas of development include:
These advancements could transform how LLMs handle extended interactions, making them more adaptable and effective for tasks that require sustained focus and continuity.
Until these innovations are widely implemented, understanding and adapting to the quirks of CDS remains critical. By employing strategies like summarization, external notes, and precise prompts, we can navigate the limitations of current LLMs while benefiting from their remarkable capabilities. The future of AI is bright, but even today, with the right approach, these tools can offer tremendous value.
Understanding CDS is not just about managing frustration–it is about appreciating the intricacies of how LLMs work and using that knowledge to collaborate with them more effectively. The more we adapt, the more we can unlock their full potential.