XSEDE is Awesome
Wednesday November 08, 2017


I’ll be writing about my trip to Goddard in the next week or so. But first, I feel like I should write about this Comet I have been playing a bit with. When I was a kid, supercomputers were these giant mythical beasts. We didn’t know what they were good for, but we knew NASA and Lawrence Livermore had them. They must be cool. Of course, there was one in Wargames:
Around the mid 1990, some guys at Goddard figured out a way to link a network of workstations into a high throughput computer and called it a Beowulf cluster. Then a group at Oak Ridge built a Beowulf cluster from surplus desktops, calling it the Stone Soupercomputer after an old children’s story. Early supercomputers were just faster and faster than what else was available. But the basics of Beowulf now underlie how most advanced computing operates. It didn’t matter because I never had any problems that interesting, anyway.
Suffice it to say I do today and the problem stems from demographic modelling. More details will come from that later, but the neat thing is, access to that kind of equipment is just dead simple in
Even better, they will give you a 1000-hour trial account just for the asking. This trial account is on Comet at the San Diego Supercomputer Center (SDSC). Comet is a 1,944-node system with 24 cores/node for 46,656 total computing cores. There are additional large memory and GPU cores available, too. But I left those off. I used the trial account to build a test implementation of my demographic simulation in R. Once I was happy it worked, I submitted an application for a startup allocation. All this takes a biosketch (a kind of specially formatted CV) and a project abstract (mine was less than 200 words). I requested 35,000 compute hours and 50 gigabytes of storage space on Comet. There are other resources available, but my code was already tested and working on Comet.
My simulation consists of two independent components. One ran overnight starting on Monday and is complete. It took approximately 210 total compute hours to run, but was done by 2 A.M. It required 11 cores on each of 10 subjobs for 110 total cores. The second kicked off tonight and will take quite a bit longer…but probably less than 48 hours, total, across all jobs.
The only real requirement, other than being of some scientific validity, as the abstract verified, is that I acknowledge my use of XSEDE’s resources when I talk about my project. That’s kind of awesome. I can even monitor the whole thing from my phone.
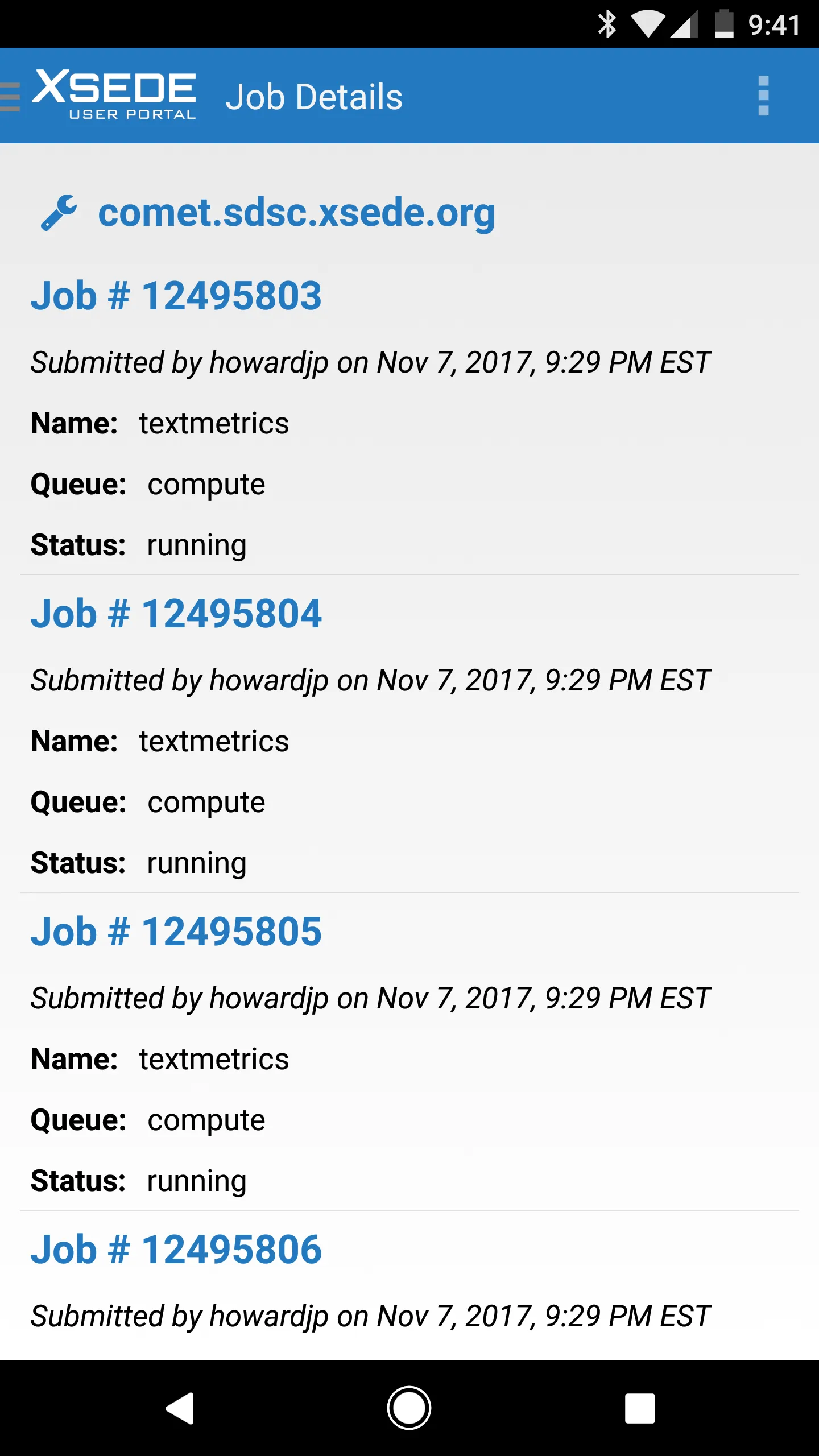
Just for reference, there are currently 644 jobs running on Comet and I am 100 of them, taking up 2400 cores.
Image by the San Diego Supercomputer Center. This work used the Extreme Science and Engineering Discovery Environment (XSEDE), which is supported by National Science Foundation grant number ACI-1548562. In particular, it used the Comet system at the San Diego Supercomputing Center (SDSC) through allocations TG-DBS170012 and TG-ASC150024.