Toggle navigation
About Me
Scholarship
Teaching
Service
Blog
Contact Me
By using our site you agree to our use of cookies to deliver a better site experience. Find out more
here
.
Reject
Accept
All Posts With Tag R
2020
Monday October 12, 2020
Phonics in JSS
•
phonics
•
articles
•
R
•
XSEDE
•
data science
•
demography
•
computational linguistics
•
2018
Sunday November 11, 2018
Parallelized Implementation of bootCI for DCchoice
•
economics
•
environmental studies
•
HPC
•
parallel computing
•
R
•
rstats
•
willingness to pay
•
SciServer
•
2017
Tuesday June 13, 2017
Computational Methods for Numerical Analysis is Out Now!
•
CMNA
•
data science
•
mathematics
•
numerical analysis
•
R
•
scientific computing
•
2016
Sunday October 23, 2016
My Review of Monogan's Political Analysis Using R
•
mathematics
•
public affairs
•
public affairs education
•
public economics
•
R
•
statistics
•
Tuesday July 26, 2016
Of Course NaN^0 = 1
•
c
•
data science
•
floating point arithmetic
•
hardware engineering
•
mathematics
•
numbers
•
R
•
scientific computing
•
systems engineering
•
systems science
•
Monday July 18, 2016
NaN versus NA in R
•
CMNA
•
data science
•
mathematics
•
missing data
•
R
•
scientific computing
•
statistics
•
Wednesday March 30, 2016
Phonics v0.7.3 with Cologne Phonetic
•
data science
•
linguistics
•
mathematics
•
phonetics
•
phonics
•
R
•
scientific computing
•
Tuesday February 16, 2016
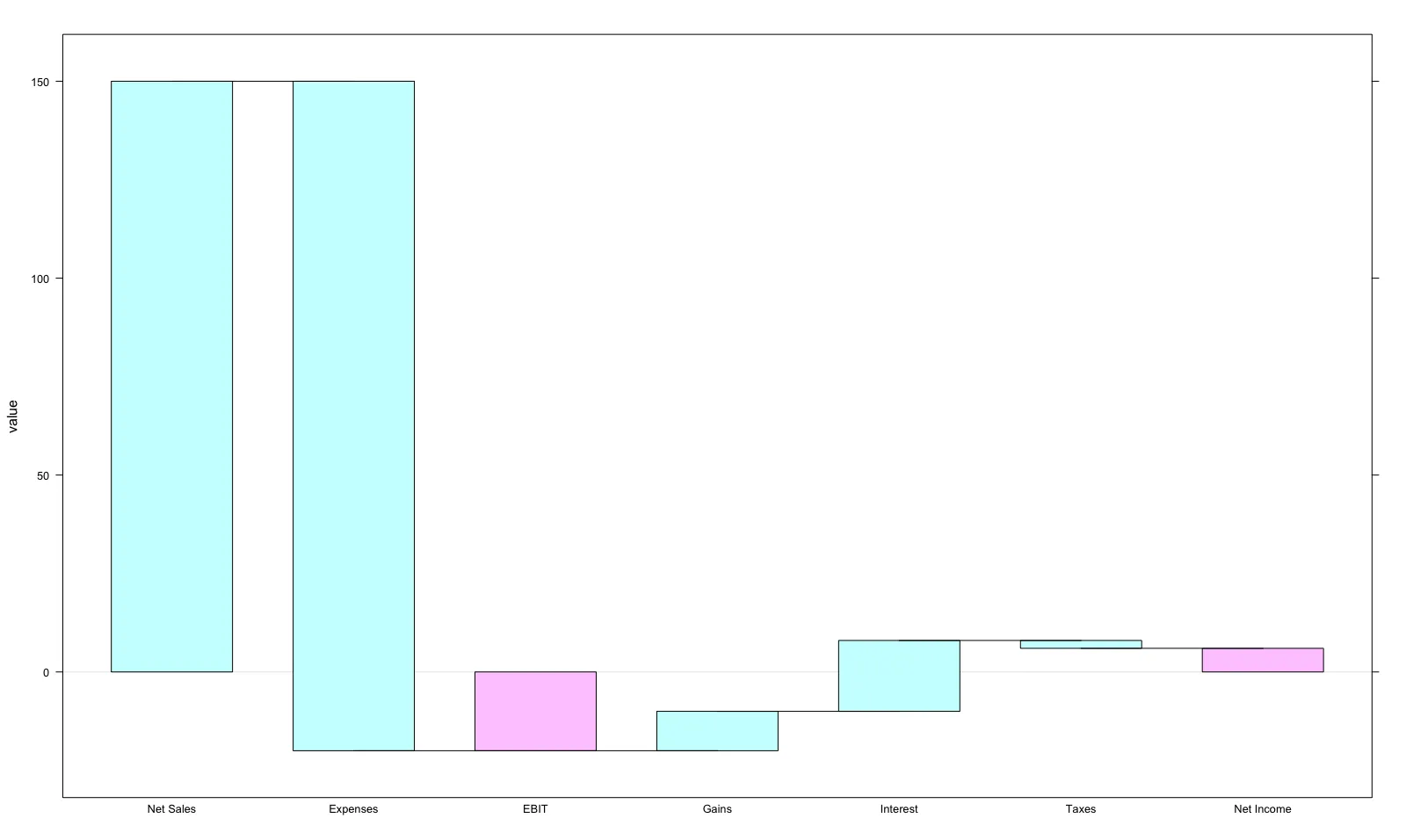
waterfall 1.0.0 released
•
data science
•
data visualization
•
graphics
•
mathematics
•
R
•
scientific computing
•
statistics
•
waterfall
•
Saturday January 09, 2016
Phonics 0.6.1 Released
•
data science
•
linguistics
•
mathematics
•
phonetics
•
phonics
•
R
•
scientific computing
•
2015
Monday December 28, 2015
Phonics is Now on CRAN
•
data science
•
linguistics
•
mathematics
•
phonetics
•
phonics
•
R
•
scientific computing
•
text analysis
•
Thursday December 24, 2015
Soundex in Phonics
•
data science
•
linguistics
•
mathematics
•
Metaphone
•
phonetics
•
phonics
•
R
•
scientific computing
•
software
•
source code
•
systems science
•
text analysis
•
Wednesday December 09, 2015
Numerical Analysis talk at Statistical Programming DC
•
CMNA
•
data science
•
mathematics
•
matlab
•
numerical analysis
•
R
•
scientific computing
•
talks
•
videos
•
Wednesday December 02, 2015
Numerical Analysis in R at Data Community DC
•
data science
•
mathematics
•
numerical analysis
•
presentations
•
R
•
scientific computing
•
Monday September 28, 2015
Caverphone, NYSIIS, and StatCan Added to Phonics Package
•
data science
•
free stuff
•
linguistics
•
mathematics
•
Metaphone
•
phonetics
•
phonics
•
R
•
scientific computing
•
software
•
source code
•
systems science
•
text analysis
•
Sunday September 20, 2015
Metaphone in R
•
data science
•
free stuff
•
linguistics
•
mathematics
•
Metaphone
•
phonetics
•
phonics
•
R
•
scientific computing
•
software
•
source code
•
systems science
•
text analysis
•
Wednesday July 29, 2015
The Value of Working Code
•
data science
•
mathematics
•
matlab
•
R
•
reviews
•
scientific computing
•
writing
•
Monday April 20, 2015
Matrix Row Echelon Form in R
•
CMNA
•
data science
•
linear algebra
•
linear equations
•
mathematics
•
matrix algebra
•
numerical analysis
•
R
•
scientific computing
•
2012
Wednesday October 31, 2012
Simply Statistics: On weather forecasts, Nate Silver, and the politicization of statistical illiteracy
•
data science
•
innumeracy
•
mathematics
•
R
•
scientific computing
•
statistics
•
2010
Sunday May 23, 2010
Waterfall Charts in R
•
data science
•
finance
•
graphics
•
mathematics
•
R
•
scientific computing
•
statistics
•
waterfall
•