Toggle navigation
About Me
Scholarship
Teaching
Service
Blog
Contact Me
By using our site you agree to our use of cookies to deliver a better site experience. Find out more
here
.
Reject
Accept
All Posts With Tag data science
2021
Thursday November 18, 2021
Seeing the Future: Predicting Irregular Leadership Changes
•
data science
•
international affairs
•
predictive analytics
•
public affairs
•
systems science
•
2020
Monday October 12, 2020
Phonics in JSS
•
phonics
•
articles
•
R
•
XSEDE
•
data science
•
demography
•
computational linguistics
•
Thursday April 16, 2020
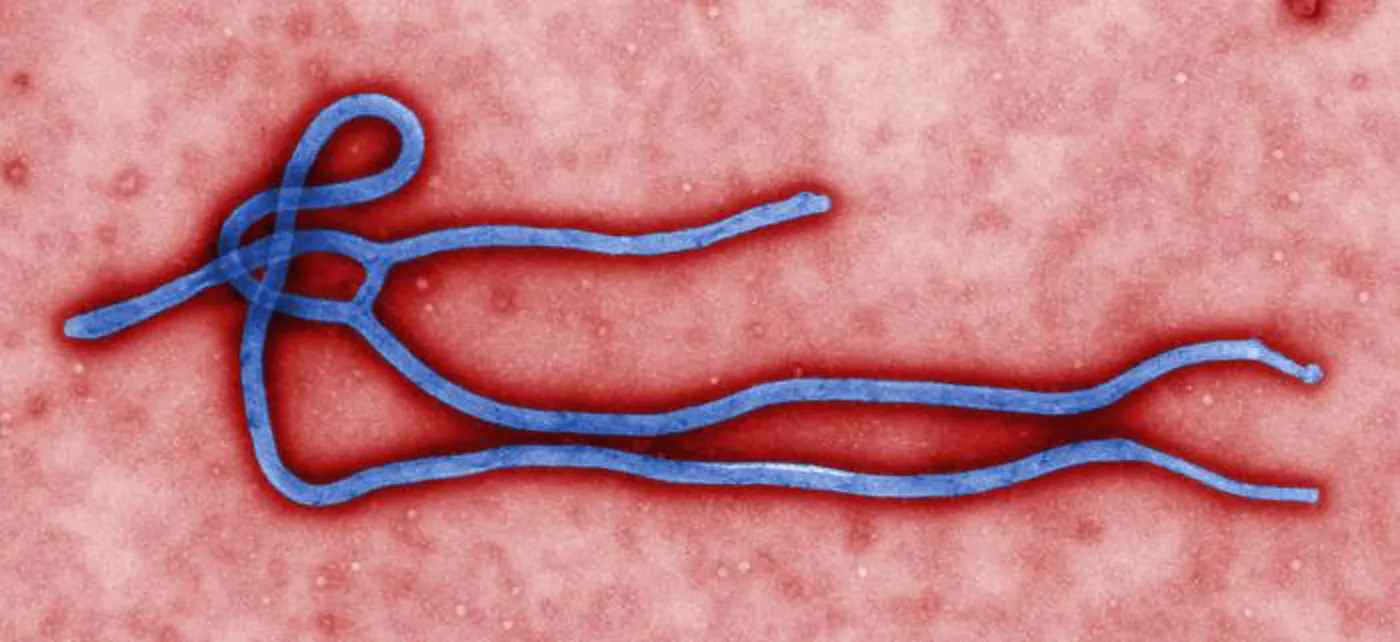
Ebolavirus Transmission at JSM2020
•
Ebola
•
data science
•
public health
•
statistics
•
epidemics
•
hemorrhagic fever
•
transmissibility
•
Monday April 13, 2020
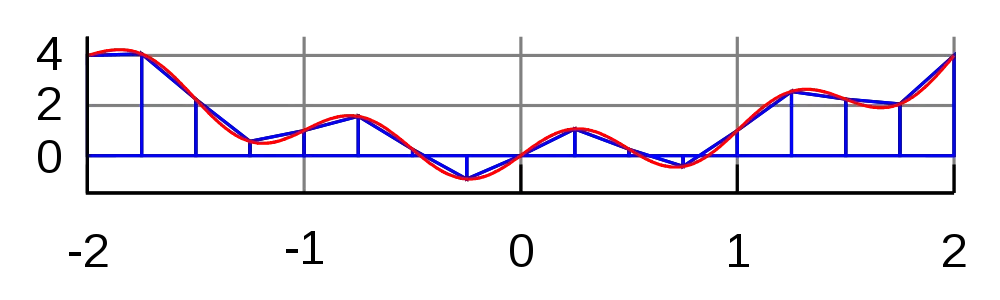
Dimensionality Reduction Through SVD
•
linear algebra
•
machine learning
•
data science
•
matrix theory
•
2019
Monday November 11, 2019
[latex]p[/latex]-hacking and Data Science
•
business
•
data science
•
statistics
•
Saturday May 25, 2019
How Data Science Happens
•
data science
•
mathematics
•
MDOR
•
systems science
•
2018
Friday March 30, 2018
My Orbit Population Model at JSM
•
data science
•
Joint Statistical Meetings
•
space systems engineering
•
systems science
•
Wednesday March 07, 2018
Disruptive Event Prediction
•
data science
•
international affairs
•
predictive analytics
•
public affairs
•
systems science
•
Monday February 19, 2018
Data Science Overhype
•
consulting
•
data science
•
information technology
•
systems engineering
•
Wednesday February 14, 2018
Phonics in JOSS, version 1.0.0 released
•
data science
•
demography
•
JOSS
•
mathematics
•
papers
•
phonics
•
XSEDE
•
2017
Tuesday September 19, 2017
Analytical Approaches for Organic Compound Properties
•
analytical chemistry
•
data science
•
environmental science
•
machine learning
•
mathematics
•
organic chemistry
•
scientific computing
•
Tuesday June 13, 2017
Computational Methods for Numerical Analysis is Out Now!
•
CMNA
•
data science
•
mathematics
•
numerical analysis
•
R
•
scientific computing
•
Tuesday April 25, 2017
Implications of Coarse Data Allocation Methods for Flood Mitigation Analysis
•
data science
•
demography
•
environmental policy
•
environmental studies
•
flood insurance
•
mathematics
•
NFIP
•
working papers
•
2016
Tuesday September 20, 2016
Announcing Computational Methods for Numerical Analysis
•
CMNA
•
data science
•
math education
•
mathematics
•
numerical analysis
•
real analysis
•
scientific computing
•
writing
•
Tuesday August 16, 2016
Deep Analytics and Big Data
•
analytics
•
big data
•
data science
•
data science press
•
mathematics
•
scientific computing
•
Tuesday July 26, 2016
Of Course NaN^0 = 1
•
c
•
data science
•
floating point arithmetic
•
hardware engineering
•
mathematics
•
numbers
•
R
•
scientific computing
•
systems engineering
•
systems science
•
Monday July 18, 2016
NaN versus NA in R
•
CMNA
•
data science
•
mathematics
•
missing data
•
R
•
scientific computing
•
statistics
•
Wednesday June 01, 2016
Things That Make You Go Hmm, Brookings Edition
•
criminal justice
•
criminology
•
data science
•
labor economics
•
mathematics
•
scientific computing
•
statistics
•
Tuesday April 26, 2016
Advice for Deploying Agile Analytics
•
agile
•
analytics
•
computer science
•
data management
•
data science
•
enterprise architecture
•
information technology
•
mathematics
•
press
•
scientific computing
•
software engineering
•
systems science
•
Wednesday April 13, 2016
Listen to me talk data science on KFNX's TechTalk
•
artificial intelligence
•
business
•
data science
•
futures studies
•
mathematics
•
press
•
radio
•
scientific computing
•
teaching
•
Friday April 08, 2016
Review of Meta-Analysis with R in JSS
•
data science
•
mathematics
•
research
•
reviews
•
scientific computing
•
statistics
•
Wednesday March 30, 2016
Phonics v0.7.3 with Cologne Phonetic
•
data science
•
linguistics
•
mathematics
•
phonetics
•
phonics
•
R
•
scientific computing
•
Tuesday February 16, 2016
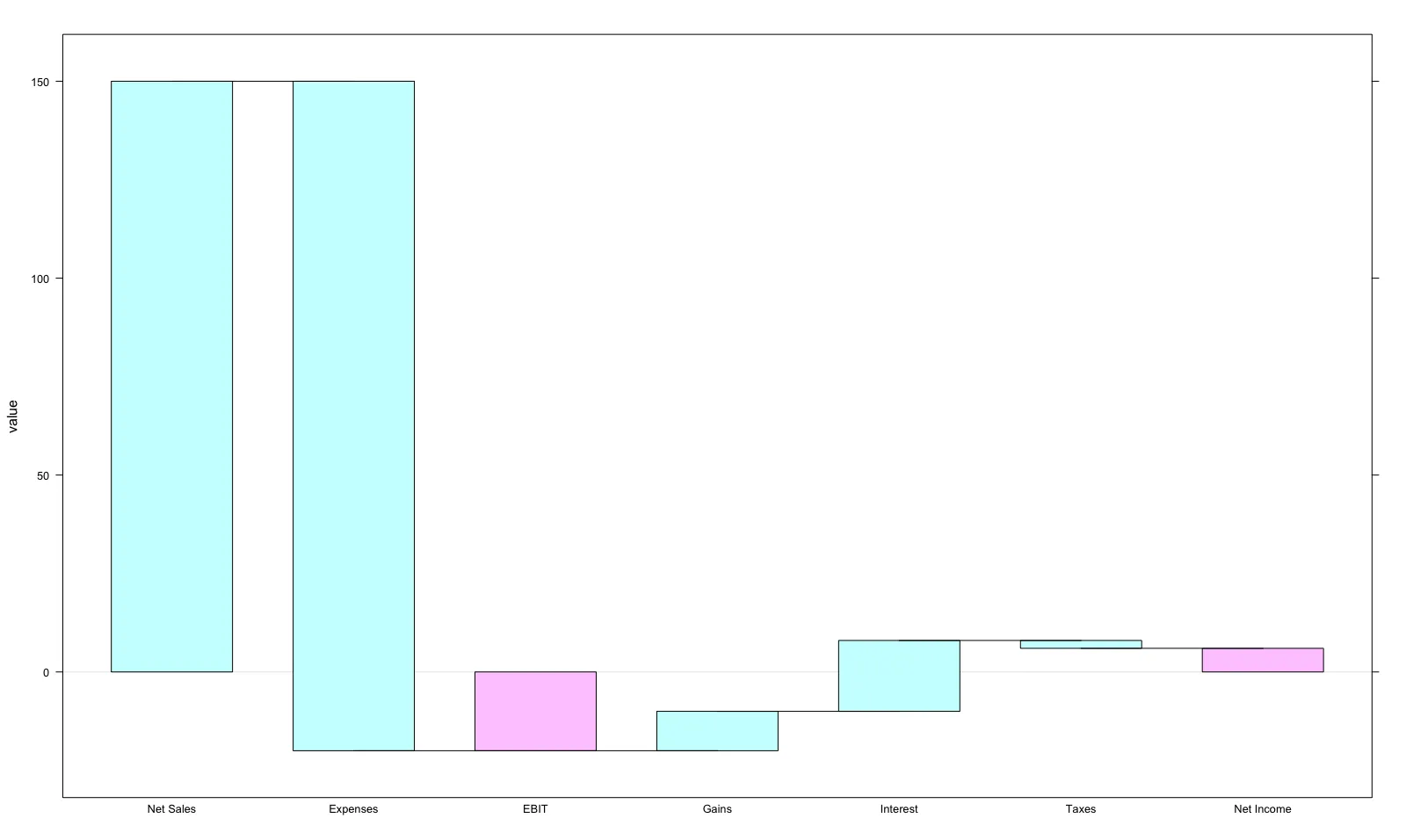
waterfall 1.0.0 released
•
data science
•
data visualization
•
graphics
•
mathematics
•
R
•
scientific computing
•
statistics
•
waterfall
•
Sunday February 14, 2016
Big Data in the Online Classroom
•
data science
•
distance education
•
education policy
•
math education
•
mathematics
•
predictive analytics
•
scientific computing
•
Monday February 01, 2016
CMNA v0.1.0 Released
•
books
•
CMNA
•
data science
•
mathematics
•
numerical analysis
•
scientific computing
•
Wednesday January 27, 2016
Inspiring Books
•
artificial intelligence
•
artificial life
•
data science
•
information science
•
libraries
•
mathematics
•
scientific computing
•
systems science
•
virtual bumblebees
•
Saturday January 09, 2016
Phonics 0.6.1 Released
•
data science
•
linguistics
•
mathematics
•
phonetics
•
phonics
•
R
•
scientific computing
•
2015
Monday December 28, 2015
Phonics is Now on CRAN
•
data science
•
linguistics
•
mathematics
•
phonetics
•
phonics
•
R
•
scientific computing
•
text analysis
•
Thursday December 24, 2015
Soundex in Phonics
•
data science
•
linguistics
•
mathematics
•
Metaphone
•
phonetics
•
phonics
•
R
•
scientific computing
•
software
•
source code
•
systems science
•
text analysis
•
Wednesday December 09, 2015
Numerical Analysis talk at Statistical Programming DC
•
CMNA
•
data science
•
mathematics
•
matlab
•
numerical analysis
•
R
•
scientific computing
•
talks
•
videos
•
Friday December 04, 2015
Pigeon Flocks for Decision Science
•
animal behavior
•
data science
•
machine learning
•
mathematics
•
neural networks
•
oncology
•
pigeons
•
radiology
•
scientific computing
•
statistics
•
Wednesday December 02, 2015
Numerical Analysis in R at Data Community DC
•
data science
•
mathematics
•
numerical analysis
•
presentations
•
R
•
scientific computing
•
Friday October 09, 2015
Data science and scientific computing book reviews
•
book reviews
•
data science
•
mathematics
•
scientific computing
•
Monday September 28, 2015
Caverphone, NYSIIS, and StatCan Added to Phonics Package
•
data science
•
free stuff
•
linguistics
•
mathematics
•
Metaphone
•
phonetics
•
phonics
•
R
•
scientific computing
•
software
•
source code
•
systems science
•
text analysis
•
Sunday September 20, 2015
Metaphone in R
•
data science
•
free stuff
•
linguistics
•
mathematics
•
Metaphone
•
phonetics
•
phonics
•
R
•
scientific computing
•
software
•
source code
•
systems science
•
text analysis
•
Wednesday September 09, 2015
How Many Floating Point Numbers are There?
•
CMNA
•
computer science
•
data science
•
math education
•
mathematics
•
numerical analysis
•
scientific computing
•
Sunday August 23, 2015
Wir sind die Roboter
•
data science
•
ethics
•
futures studies
•
intellectual property
•
mathematics
•
predictive analytics
•
retrofuturism
•
robots
•
scientific computing
•
Wednesday August 12, 2015
Stop Making 3D Plots
•
data science
•
math education
•
mathematics
•
scientific computing
•
statistics
•
visualization
•
Thursday July 30, 2015
Comments on Logarithmic Measurements
•
college algebra
•
data science
•
logarithms
•
math education
•
mathematics
•
measurement
•
scientific computing
•
trigonometry
•
Wednesday July 29, 2015
The Value of Working Code
•
data science
•
mathematics
•
matlab
•
R
•
reviews
•
scientific computing
•
writing
•
Tuesday July 28, 2015
Comments on Logarithmic Bases
•
algebra
•
data science
•
logarithms
•
math education
•
mathematics
•
scientific computing
•
trigonometry
•
Saturday June 13, 2015
Decibels
•
data science
•
engineering
•
logarithms
•
mathematics
•
measurement
•
planetary science
•
science
•
scientific computing
•
sound
•
TIL
•
Tuesday May 19, 2015
On Being Right and Being Flexible
•
data science
•
enterprise architecture
•
information technology
•
mathematics
•
public affairs
•
public affairs education
•
public economics
•
public financial management
•
scientific computing
•
software engineering
•
systems science
•
teaching
•
Wednesday April 22, 2015
Analytics as a Service in the Enterprise
•
AaaS
•
computer science
•
data science
•
enterprise architecture
•
information technology
•
mathematics
•
scientific computing
•
software engineering
•
systems science
•
Monday April 20, 2015
Matrix Row Echelon Form in R
•
CMNA
•
data science
•
linear algebra
•
linear equations
•
mathematics
•
matrix algebra
•
numerical analysis
•
R
•
scientific computing
•
2014
Tuesday October 21, 2014
Big Data for Locals
•
analytics
•
big data
•
data science
•
futures studies
•
Howard County
•
mathematics
•
public administration
•
public affairs
•
public policy
•
scientific computing
•
Sunday June 22, 2014
Review of the INFORMS Analytics Maturity Model
•
business
•
data science
•
mathematics
•
scientific computing
•
statistics
•
2013
Thursday August 22, 2013
My letter in Significance Magazine...
•
data science
•
Flintstones
•
letters
•
mathematics
•
scientific computing
•
statistics
•
Yogi Bear
•
2012
Saturday November 10, 2012
Who run Bartertown?
•
data science
•
mathematics
•
Obama
•
Romney
•
science
•
scientific computing
•
Wednesday October 31, 2012
Simply Statistics: On weather forecasts, Nate Silver, and the politicization of statistical illiteracy
•
data science
•
innumeracy
•
mathematics
•
R
•
scientific computing
•
statistics
•
Saturday January 28, 2012
Fiscal Year CPI Indicators
•
cpi
•
data
•
data science
•
economic analysis
•
economics
•
inflation
•
mathematics
•
scientific computing
•
Wednesday January 04, 2012
Recoding County-Level Data
•
counties
•
data
•
data science
•
environmental policy
•
environmental studies
•
FEMA
•
flood mitigation
•
flood studies
•
mathematics
•
scientific computing
•
2010
Sunday May 23, 2010
Waterfall Charts in R
•
data science
•
finance
•
graphics
•
mathematics
•
R
•
scientific computing
•
statistics
•
waterfall
•