Toggle navigation
About Me
Scholarship
Teaching
Service
Blog
Contact Me
By using our site you agree to our use of cookies to deliver a better site experience. Find out more
here
.
Reject
Accept
All Posts With Tag statistics
2023
Sunday November 05, 2023
How Math Influences Legal Decisions
•
statistics
•
forensics
•
criminal justice
•
fingerprint analysis
•
wrongful conviction
•
Thursday November 02, 2023
What is Stochastic Calculus?
•
mathematics
•
statistics
•
calculus
•
2020
Tuesday May 19, 2020
The Risk of Dying From COVID-19
•
public health
•
statistics
•
mortality
•
COVID-19
•
SARS
•
MERS
•
influenza
•
Tuesday May 12, 2020
Teaching and Learning Mathematics Online is Published
•
TLMO
•
math education
•
statistics
•
COVID-19
•
mathematics
•
Friday April 24, 2020
The Challenge of Assessment and Evaluation in Online Education
•
COVID-19
•
online education
•
mathematics education
•
statistics
•
mathematics
•
Thursday April 16, 2020
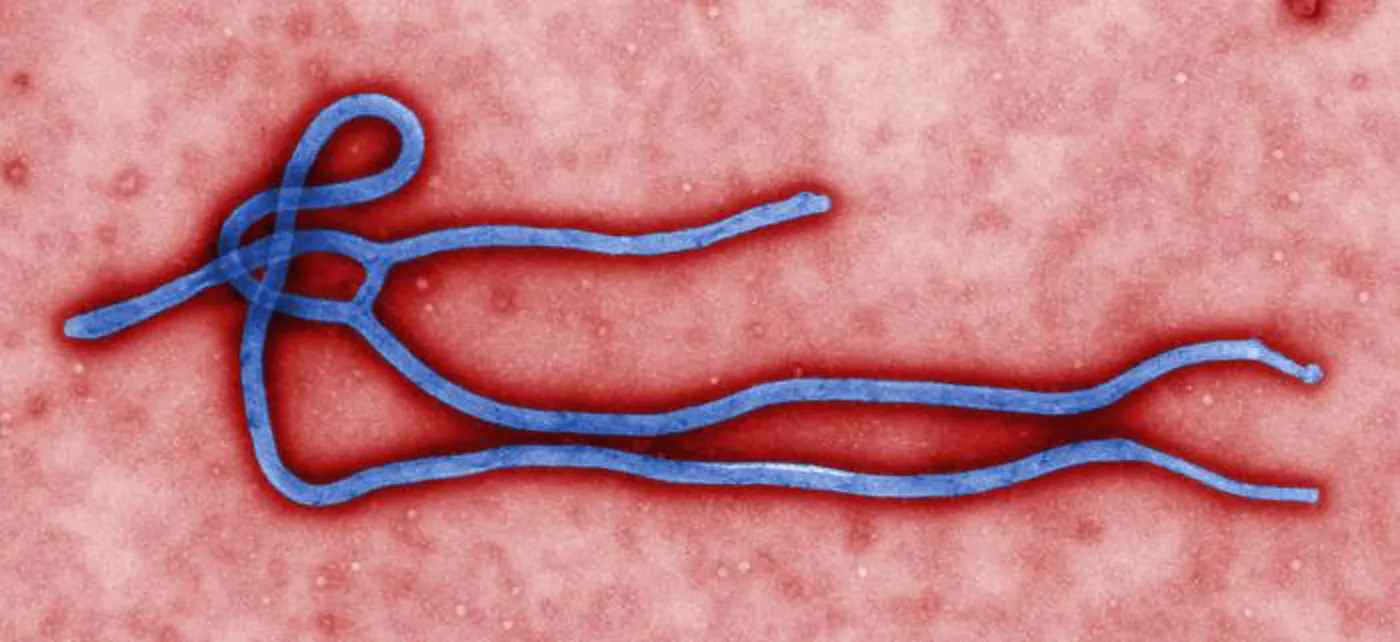
Ebolavirus Transmission at JSM2020
•
Ebola
•
data science
•
public health
•
statistics
•
epidemics
•
hemorrhagic fever
•
transmissibility
•
Tuesday March 31, 2020
A Brief Discourse on the Jackknife Method
•
computational statistics
•
computer science
•
numerical analysis
•
statistics
•
Tuesday February 18, 2020
Shotgun Pi
•
mathematics
•
Open Science Grid
•
statistics
•
2019
Monday November 11, 2019
[latex]p[/latex]-hacking and Data Science
•
business
•
data science
•
statistics
•
Sunday October 06, 2019
Bracewell Was Awesome
•
astrobiology
•
astronomy
•
statistics
•
Saturday September 07, 2019
Monte Carlo Simulation Advantages and Disadvantages
•
Monte Carlo simulation
•
probability
•
simulation
•
statistics
•
SciServer
•
2018
Wednesday October 03, 2018
Rainfall Stationarity
•
environmental studies
•
meteorology
•
rainfall
•
statistics
•
Friday January 12, 2018
Audio and Slides from My Talk at JMM
•
Joint Mathematical Meetings
•
math anxiety
•
mathematics
•
popular mathematics
•
San Diego
•
statistics
•
Friday January 05, 2018
JMM in San Diego Next Week
•
Joint Mathematical Meetings
•
knot theory
•
mathematics
•
neural networks
•
popular mathematics
•
San Diego
•
statistics
•
topology
•
2017
Wednesday August 09, 2017
Syllabus for Introduction to Statistics
•
math education
•
mathematics
•
statistics
•
TLMO
•
UMGC
•
Saturday August 05, 2017
I Thought the Generals Were Due!
•
lottery
•
math education
•
mathematics
•
megamillions
•
probability
•
risk
•
statistics
•
The Simpsons
•
Friday August 04, 2017
Halloween Changes to Mega Millions Scare Some
•
lottery
•
math education
•
mathematics
•
megamillions
•
statistics
•
Sunday March 12, 2017
Gelman's Candy Weighing Demonstration
•
Central Michigan University
•
management education
•
math education
•
mathematics
•
statistics
•
2016
Sunday October 23, 2016
My Review of Monogan's Political Analysis Using R
•
mathematics
•
public affairs
•
public affairs education
•
public economics
•
R
•
statistics
•
Saturday September 03, 2016
The Severity of Severe Events is Increasing
•
Earth science
•
environmental policy
•
environmental science
•
environmental studies
•
flood studies
•
global climate change
•
Howard County
•
mathematics
•
statistics
•
weather
•
Friday September 02, 2016
What is a 100-year flood?
•
environmental policy
•
environmental science
•
environmdental studies
•
flooding
•
Howard County
•
mathematics
•
statistics
•
weather
•
Wednesday August 10, 2016
Statistical Likelihood of Extreme Events and the Ellicott City Floods
•
Earth science
•
environmental policy
•
environmental science
•
environmental studies
•
flood studies
•
Howard County
•
mathematics
•
risk management
•
statistics
•
Monday July 18, 2016
NaN versus NA in R
•
CMNA
•
data science
•
mathematics
•
missing data
•
R
•
scientific computing
•
statistics
•
Saturday July 02, 2016
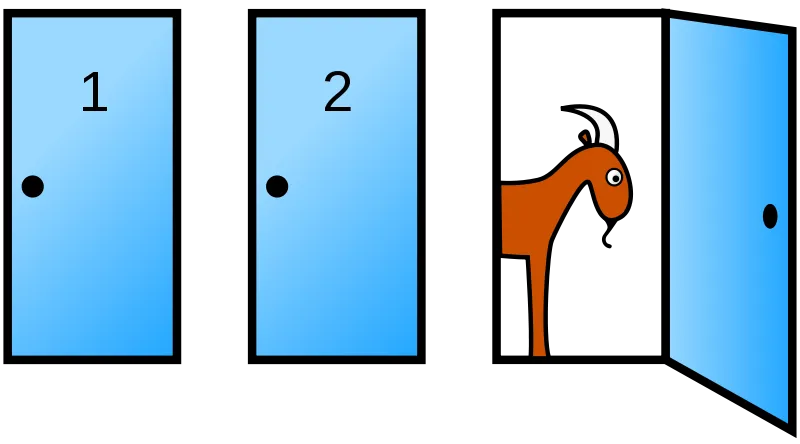
Thoughts on Monty Hall
•
Bayes theorem
•
game shows
•
mathematics
•
Monty Hall problem
•
popular mathematics
•
risk
•
risk analysis
•
statistics
•
Friday July 01, 2016
Someone Will Win and It Probably Won't Be You
•
games
•
lottery
•
math education
•
mathematics
•
statistics
•
Wednesday June 01, 2016
Things That Make You Go Hmm, Brookings Edition
•
criminal justice
•
criminology
•
data science
•
labor economics
•
mathematics
•
scientific computing
•
statistics
•
Friday April 08, 2016
Review of Meta-Analysis with R in JSS
•
data science
•
mathematics
•
research
•
reviews
•
scientific computing
•
statistics
•
Friday April 01, 2016
JSM 2016
•
Earth science
•
economics
•
environmental policy
•
environmental studies
•
mathematics
•
public affairs
•
public economics
•
public finance
•
public financial management
•
research
•
social discount rates
•
statistics
•
talks
•
Tuesday February 16, 2016
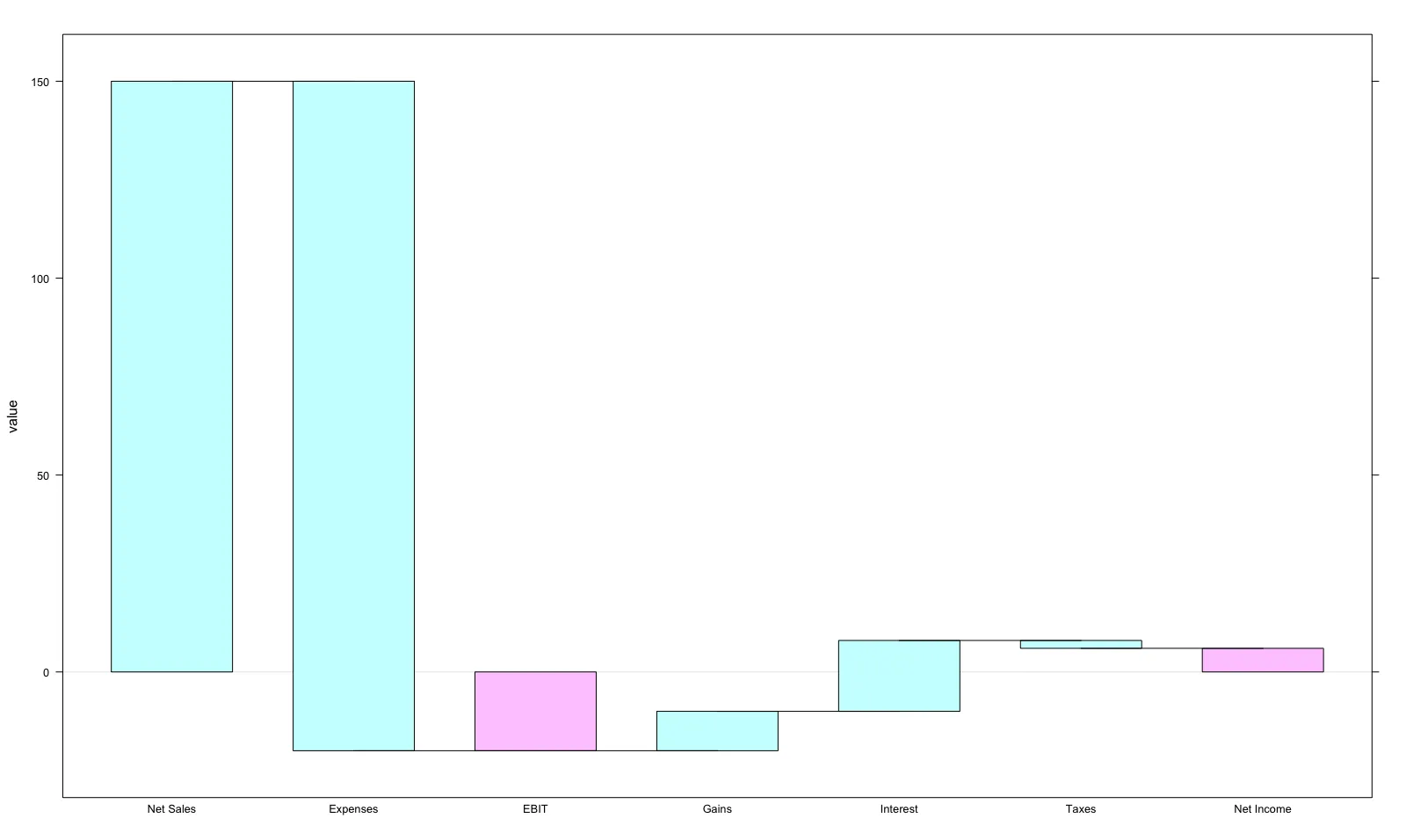
waterfall 1.0.0 released
•
data science
•
data visualization
•
graphics
•
mathematics
•
R
•
scientific computing
•
statistics
•
waterfall
•
2015
Friday December 04, 2015
Pigeon Flocks for Decision Science
•
animal behavior
•
data science
•
machine learning
•
mathematics
•
neural networks
•
oncology
•
pigeons
•
radiology
•
scientific computing
•
statistics
•
Monday October 12, 2015
1000-year storms in South Carolina
•
Earth science
•
environmental policy
•
environmental science
•
environmental studies
•
flood studies
•
mathematics
•
risk
•
South Carolina
•
statistics
•
Wednesday August 12, 2015
Stop Making 3D Plots
•
data science
•
math education
•
mathematics
•
scientific computing
•
statistics
•
visualization
•
Tuesday April 14, 2015
Why I Bought a Mega Millions Ticket
•
lottery
•
Maryland
•
mathematics
•
risk
•
statistics
•
Monday April 13, 2015
Maryland Lottery Proceeds Don't Pay for Education
•
lottery
•
Maryland
•
mathematics
•
public affairs
•
public economics
•
public financial management
•
statistics
•
2014
Sunday November 30, 2014
Radiolab loses at statistics
•
bad math
•
fair coin
•
math education
•
mathematics
•
statistics
•
Thursday July 17, 2014
Teaching Finite Mathematics
•
math education
•
mathematics
•
statistics
•
teaching
•
UMGC
•
Sunday June 22, 2014
Review of the INFORMS Analytics Maturity Model
•
business
•
data science
•
mathematics
•
scientific computing
•
statistics
•
Wednesday April 09, 2014
The National Science Foundation Finds Ignorance
•
education
•
mathematics
•
policy
•
science policy
•
statistics
•
Thursday April 03, 2014
A Theorem on the Consumer Surplus
•
demand
•
economic analysis
•
economics
•
environmental policy
•
environmental studies
•
flood studies
•
mathematics
•
statistics
•
2013
Thursday August 22, 2013
My letter in Significance Magazine...
•
data science
•
Flintstones
•
letters
•
mathematics
•
scientific computing
•
statistics
•
Yogi Bear
•
2012
Wednesday October 31, 2012
Simply Statistics: On weather forecasts, Nate Silver, and the politicization of statistical illiteracy
•
data science
•
innumeracy
•
mathematics
•
R
•
scientific computing
•
statistics
•
2010
Sunday May 23, 2010
Waterfall Charts in R
•
data science
•
finance
•
graphics
•
mathematics
•
R
•
scientific computing
•
statistics
•
waterfall
•